Introducing Populus: Simulating Life at UC Berkeley
At The Residency’s Hackathon hosted at UC Berkeley, we built Populus — an agent-based simulation that visualizes the stochastic lives of the people at Berkeley.
Populus (latin: people) is a tool for understanding community dynamics. Essentially, it’s Sim City meets UC Berkeley and instead of building infrastructure, you’re uncovering the daily routines.
welcome to populus!
It was just a regular day…
Pullin’ up to the Residency House, we were met with hella people and HELLA ideas. After two hours of brainstorming, we came up with nothing but an impossible project and a heavy time gap to fill if we were gonna finish.
Soon after the opening ceremony, we found ourselves hungry for some low rate pizza — and left the house just to be met with three drunk frat boys trying to decipher whose t-shirt was who’s. From the bums of Berkeley walking outside the front door to the bums of Berkeley sitting across from us at the lunch table, we were met with one simple epiphany:
How would my day look if I were a Berkeley bum?
People are inherently complex structures (especially the baddies), but a major problem within artificial agent literature has been simulating our tendencies and actions. Inspired by our revelation, we hoped to structure our project around these two topics. Could it be possible to use off-the-shelf state-of-the-art technologies to shoot at this moonshot problem?

Strategy 1: Designing a multi-agentic system within Berkeley
Our first idea was absolutely amazing. Just kidding, it kinda sucked but we tried it anyways. We attempted to create a system that utilized multiple AI agents to create both prompts for how students navigate their day and also where they might go.
This caused mainly two issues:
- The cost effectiveness and speed of 679 quadrillion calls every time we needed to find a single bum’s daily route would be about as painful as how lazy Manit was whenever I wanted to go out to eat.
- Trying to use OpenAI to figure out the best places to go in Berkeley might not have been the best idea lowkey. Honestly, that one night out in Berkeley probably gave us, basically complete bums, a better idea of Berkeley than ChatGPT.
Like Dora the Explorer, we quickly moved on to our next spot on the map — prompting literally everything.
Strategy 2: Prompt-stuffing everything we know
We realized that GPT had no clue what spots were popular near the Berkeley campus so we picked up one of the Residency house members and interrogated them for an hour. Well actually, it was probably closer to holding them hostage than questioning to be honest (they definitely hate us now).
Anyways, apparently all we needed to know was that Unit 1 was where the action happened and Zeta Psi hosted the best parties. With this newfound enlightenment, we got lit up and high out of our minds. Joking, joking, we just made a better strategy.
Looking for the cheapest way to get places for our app, we hopped on an electric scooter and got writing down the most hood spots near us. Turns out, it was pretty inefficient so we settled with the Google Places API. We had over 1000 random places in a JSON and just shoved it into the prompt. We came out with GPT recommending the bum to eat at a laundromat for breakfast.
Interlude
Around 12:30 AM, we walked down the street to Insomnia Cookies, where we got fire pastries while witnessing an absolute masterclass of rizz (like when I say masterclass, this guy bagged a girl in a grand total of 30 seconds).
Switching gears, we started heading back up the street to get back to locking in (things were not going too well), but got distracted by the sights and sounds of the city. Swarms of snow bunnies, blocks of brown boys and ABGs, our feeble high school minds succumbed to the pressure. Like moths to a flame, we scurried towards the lights—hoping to get in on some action, if you catch my drift.
We ended up outside a frat party (or afterparty, or after-afterparty… kinda hard to tell), but unfortunately for us, that is when reality hit. The bouncers at the front looked like they were 250 pounds of lean muscle, ex-MMA fighters with years of trained jiu-jitsu and kickboxing experience. Needless to say, we did not want to try our luck. Taking our best chance though, we tried sneaking in with our fellow brown brethren but to our dismay, they were not cool enough for school either.
We walked a true walk of shame back to the Residency home, but immediately got back on the grind.


Strategy 3: Grounding the LLM with a Vector Database
After experimenting with prompt stuffing to inject location-specific realism, we realized the need for a more robust and scalable approach. That’s where the integration of a vector database with GPT-4o-mini (configured at a temperature of 0.8 for balanced creativity and coherence) changed the game. This approach marries large language models (LLMs) with structured, location-based data to craft schedules and behaviors that feel both authentic and deeply tied to the physical world.
At the core of this method is a vector database, constructed using Google’s Places API. It acts as a bridge between the LLM’s general descriptive capabilities and specific, real-world locations around the UC Berkeley campus. The database isn't just a static list of places; it's a curated collection of dorms, lecture halls, cafes, libraries, and landmarks enriched with semantic and geographic metadata. This metadata includes coordinates, contextual relevance, and typical usage patterns, making it a dynamic tool for location mapping.
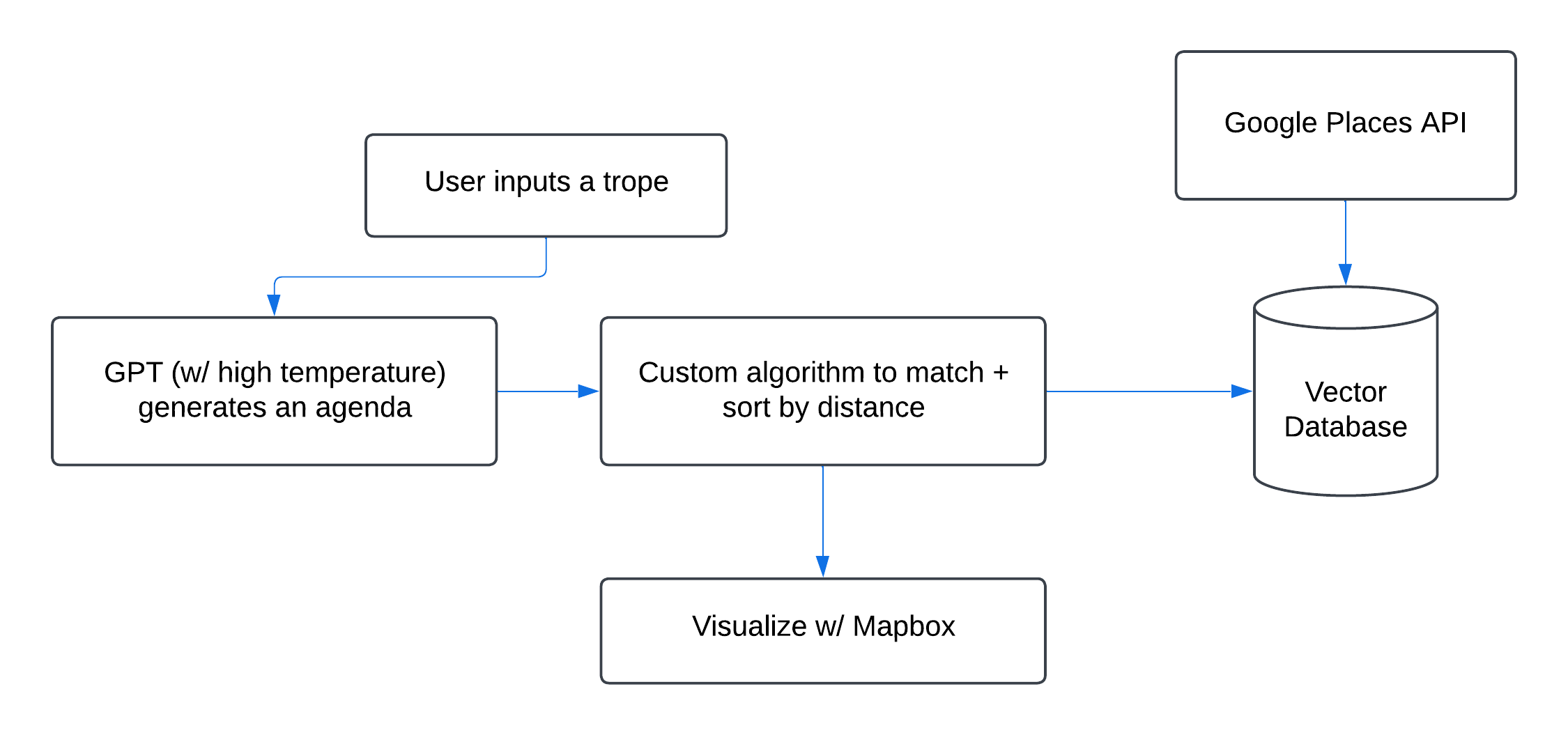
Here’s how it works: when GPT-4o-mini generates a schedule item or task for an agent—say, “grab a coffee before class” or “find a quiet spot to study”—the vector database grounds these abstract directives in real, plausible locations. For example, if the schedule includes “grab coffee,” the system identifies nearby cafes like Café Strada or FSM Café. The choice isn’t arbitrary; it’s prioritized based on the agent’s current location, proximity to subsequent activities, and the contextual suitability of the venue.
-
For context, here is how we implemented that, formatting an agenda and grounding in “home” coordinates (Unit 1) to track the agent’s locations and find the closest and most semantically similar places.
def _load(schedule: str) -> dict: schedule = yaml.safe_load(schedule) prev = (37.86744, -122.25445) locations = [] coords = [(prev[1], prev[0])] current = 0 for step in schedule["schedule"]: query = model.encode([step["activity"]]) D, I = index.search(query, k=N) distances = {} for i in range(len(I)): metadata = source[I[0][i]] distance = math.sqrt((metadata["latitude"] - prev[0]) ** 2 + (metadata["longitude"] - prev[1]) ** 2) distances[i] = distance best = min(distances.items(), key=lambda x: x[1]) best = source[I[0][best[0]]] best["id"] = current best["time"] = step["time"] best["activity"] = step["activity"] prev = (best["latitude"], best["longitude"]) coords.append((prev[1], prev[0])) current += 1 locations.append(best) idx = [i for i in range(current)] return { "locations": locations, "coords": coords, "idx": idx }
Similarly, for academic tasks like “host office hours,” the system aligns the activity with specific campus buildings such as Dwinelle Hall or other likely faculty spaces. The result? Every line of the agent’s schedule is not just a descriptive suggestion but a navigable, real-world plan.
This grounding mechanism enables Populus to move beyond generic, imagined schedules into a realm of realism where the LLM’s outputs are both plausible and actionable within the actual geography of UC Berkeley. It ensures that the simulated activities feel authentically connected to the campus’s physical and cultural fabric. By anchoring AI-driven agents to real locations, we’ve achieved a level of detail and realism that simply wasn’t possible with earlier, prompt-stuffing techniques.
Final Thoughts (and Prayers)
Beyond the tangible utility of seeing what your friends at Berkeley would be doing at 2 AM in their spare time (eg. getting wasted), Populus has many real-world applications:
With university admissions becoming increasingly competitive in recent years, students are burdened with uncovering the intricacies of their favorite university’s student culture, in many cases without ever having set foot on campus. Through widespread integration of Populus in university infrastructure, prospective students get a better sense of the activities to do around campus, equipping them for their “Why Us” essays.
Additionally, this is a solid base for development on human behavioral simulations. Currently, with location and similarity of venues to the prompts used to determine the path, our model utilizes only two variables of human behavior. However, with greater numbers of variables used for the prompt engineering, we could model human behavior in day-to-day systems.
The potential utility of Populus is endless, encapsulating everything from university admissions assistance to anthropological psychology research. However, we can all agree that the best feature is watching our perpetually hungover professor make it through his chaotic day :)
walkthrough demo!